我是如何使用 Claude Code 每一项功能的
我使用Claude Code的所有方法大盘点。
我是 ClaudeCode 的狂热爱好者。
作为一名爱好者,我每周都会在虚拟机里运行几次, 处理个人项目。
常常配合 --dangerously-skip-permissions 来随心所欲地写代码。在工作中,我所在团队的一部分负责为工程团队构建AIIDE规则和工具,仅仅是代码生成就会消耗每月数十亿个token。
基于CLI的Agent赛道愈发拥挤:Claude Code、Gemini CLI、Codex CLI、 Cursor CLI、Copilot CLI…
感觉真正的竞争在于 Anthropic 与 OpenAI 之间。
但坦白说,当我与其他开发者交流时,他们的选择往往取决于一些表面的因素——用这个工具幸运地实现了某个功能,或者他们喜欢的系统提示词的“调性”。
此时这些工具都已经相当不错了。我也觉得大家经常过度关注输出风格或界面。“你说得对!” 式的阿谀奉承其实并不是什么严重的缺陷,反而说明你已经深度参与其中,完全掌握了全局。
对我来说,把任务交出去,设定上下文,然后让它自己工作,只根据最后的PR成品来评估,而不是纠结过程
在连续几个月坚持使用 Claude Code之后,这篇文章总结了我对其整个生态系统的思考。我们会覆盖我使用的几乎所有功能(包括重要的但我不常使用的那些功能),
从基础的 CLAUDE.md 文件和自定义斜杠命令,到 Subagents、Hooks、GitHub Actions等强大能力。这篇文章篇幅较长,我更建议把它当作参考手册,而不是一次性读完。
● CLAUDE.md
在代码库里,要想高效使用 Claude Code,最重要的文件就是根目录下的CLAUDE.md。它是Agent的行为准则,是了解你这仓库运作方式的首要依据。
如何对待这个文件,要看具体场景。对于我的兴趣项目,我让Claude 想写什么就写什么。
在我的工作上,公司仓库Monorepo中的CLAUDE.md维护得非常严格,目前大小约为13KB(完全有可能增长到 25KB)。
• 它只记录大多30%(这个阈值比较随意)的工程师会用到的工具和 API(其他工具会在产品或库专属的Markdown文件里记录)。
• 我们甚至开始每个内部工具的文档分配最大token 数。 如果你不能简明扼要地解释你的工具,那它就还没准备好被放进 CLAUDE.md。
● 技巧与常见反模式
随着时间推移,我们形成了一套鲜明且有主见的写作哲学,来打造高效的CLAUDE.md。
- 先设限制,而不是写指南。 你的
CLAUDE.md应从小处着手,根据 Claude 常犯的错误来逐步记录相关内容。 - 别在
CLAUDE.md里到处 @ 引用文档。 如果你在别处已有大量文档,很容易想在CLAUDE.md里@这些文件。这会在每次运行时把整份文件塞进上下文窗口,导致臃肿。但如果你只是在文中提到路径,Claude 通常会忽略它。相反的,你必须向 Agent 推销 “为什么” 以及 “什么时候” 需要读这份文件:“遇到复杂用法或碰到 FooBarError 时,请参见 path/to/docs.md 获取最佳问题排查步骤。” - 不要只说“禁止”。 避免纯粹的负面约束,例如 “绝对不要使用 --foo-bar 标志” 当Agent认为它必须使用该标志时,就会左右脑互博,导致卡住。所以永远要提供可行的替代方案。
- 把 CLAUDE.md 当成强制性手段。 如果你的CLI 命令复杂又冗长,与其写长篇大论解释它们,不如写一个简单的bash 包装器,提供清晰直观的 API,然后记录这个包装器。保持
CLAUDE.md尽可能短,是迫使你精简代码库和内部工具的绝佳手段。
这是一个简化的示例
# Monorepo
## Python
- 总是...
- 使用 <command> 进行测试
... 还有10条 ...
## <内部 CLI 工具>
... 10个要点,聚焦于80%的使用场景 ...
- <使用示例>
- 总是...
- 禁止 <x>,优先使用 <Y>
对于 <复杂用法> 或 <错误>,请参阅 path/to/<tool>_docs.md
...
最后,我们会将这个文件与一个 AGENTS.md 文件保持同步,以确保与其他我们工程师可能在使用的 AI IDE 兼容。
核心要点:
把
CLAUDE.md当作一套高层次、精心策划的护栏和指引。用它来指导你在哪里需要投入更多精力来打造对 AI(和人类)更友好的工具,而不是试图把它变成一本无所不包的百科全书。
如果您正在寻找更多关于为编码助手编写 Markdown 的技巧,请参阅 “AI 无法读懂你的文档”、“AI 驱动的软件工程”,以及 “Cursor(AI IDE)的工作原理”.
● 上下文管理之压缩和清理
我建议在编码会话中至少运行一次 /context ,来了解你那 200k token 的上下文窗口是如何被使用的(即使是 Sonnet-1M,我也不相信完整的上下文窗口能被有效利用)。对我们来说,在我们的 monorepo 中,一个全新的会话基线成本大约是 20k token (10%),剩下的 180k 用于你的实际修改——而这很快就会被填满。
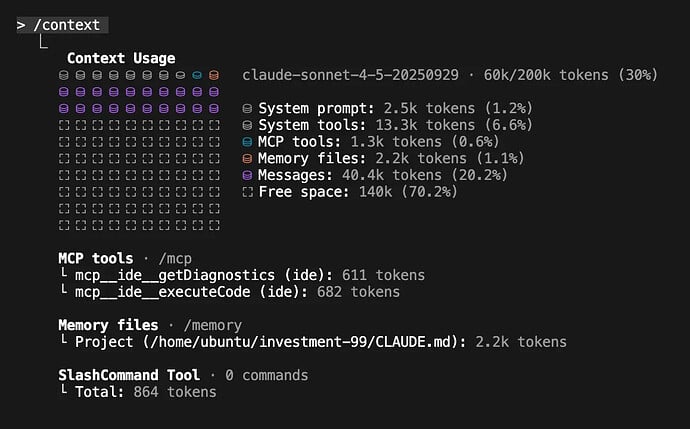
这是我最近一个个人项目中 /context 的截图。你可以把它想象成磁盘空间,随着你开发一个功能,它会逐渐被填满。几分钟或几小时后,你就需要清除消息(紫色部分)来腾出空间继续工作。
CCometixLine 超绝观测 Context Window
三个主要的工作流程:
- /compact (避免使用) 我尽可能避免使用这个命令。它的自动压缩过程不透明、容易出错,而且优化得不好。
- /clear + /catchup (简单重启) 这是我的默认重启方式。我用
/clear清除状态,然后运行一个自定义的/catchup命令,让 Claude 读取我当前 git 分支中所有已更改的文件。 - “记录并清除” (复杂重启) 用于大型任务。我让 Claude 把它的计划和进展输出到一个
.md文件中,然后用/clear清除上下文,接着通过让它读取那个.md文件来开始一个新的会话并继续工作。
核心要点:
不要相信自动压缩。对简单的重启使用
/clear,对复杂任务使用“记录并清除”的方法来创建持久的外部“记忆”。
● 自定义斜杠命令
我把斜杠命令看作是常用提示的简单快捷方式,仅此而已。我的配置非常精简:
- /catchup : 就是我前面提到的命令。它只是提示 Claude 读取我当前 git 分支中所有已更改的文件。
- /pr : 一个简单的辅助工具,用来清理我的代码、暂存更改,并准备一个 Pull Request。
恕我直言,如果你有一长串复杂的自定义斜杠命令,你就制造了一个反模式。对我来说,像 Claude 这样的Agent的全部意义就在于,你可以输入几乎任何 你想要的东西,并得到一个有用的、可合并的结果。一旦你强迫一个工程师(或非工程师)为了完成工作而去学习一个需要查文档的、新的魔法命令列表,你就失败了。
核心要点:
把斜杠命令当作简单、个人化的快捷方式,而不是用它来替代构建更直观的
CLAUDE.md和更好的工具化Agent。
● 自定义SubAgent
理论上,SubAgent是 Claude Code 在上下文管理方面最强大的功能。它的理念很简单:一个复杂任务需要 X token 的输入上下文(例如,如何运行测试),在工作过程中累积了 Y token 的上下文,并产出一个 Z token 的答案。运行 N 个这样的任务意味着你的主窗口中会有 (X + Y + Z) * N 个 token。
SubAgent的解决方案是,将 (X + Y) * N 的工作外包给专门的Agent,这些Agent只返回最终的 Z token 答案,从而保持你的主上下文清爽。
但我发现,这个强大的想法在实践中,SubAgent 会带来两个新问题:
- 它们把上下文“关起来”了 (Gatekeep Context) 如果我创建了一个
PythonTestsSubAgent,我现在就把所有关于测试的上下文从我的主 Agent那里��隐藏了。主Agent再也无法对一个变更进行整体性的思考。它现在被迫调用 SubAgent 才能知道如何验证自己的代码。 - 它们强迫 Agent 遵循人类的工作流 更糟糕的是,它们强迫 Claude 进入一个僵硬的、由人类定义的工作流。我现在是在指令它必须如何 委派任务,而这正是我希望Agent帮我解决的问题。
我更喜欢的替代方案是使用 Claude 内置的 Task(...) 功能来生成通用 代理的克隆体。
我把所有关键上下文都放在 CLAUDE.md 里。然后,我让主Agent 自己决定何时以及如何将工作委派给它自己的副本。这让我既享受了SubAgent节省上下文的好处,又避免了其缺点。Agent可以动态地管理自己的协作流程。
在我的 《构建Multi Agent System(第二部分)》 一文中,我将这种架构称为“主-克隆”模式,并且强烈推荐它,而非定制 SubAgent 所倡导的“主导-专家”模型。
核心要点:
自定义 SubAgent 是一个脆弱的解决方案。把上下文给你的主Agent(放在
CLAUDE.md里),让它使用自己的Task/Explore(...)功能来管理任务委派。
● 恢复、继续与历史记录
在简单的层面上,我经常使用 claude --resume 和 claude --continue 。它们对于重启一个出问题的终端或快速恢复一个旧的会话非常好用�。我常常会 claude --resume 一个几天前的会话,只为了问Agent它是如何克服某个特定错误的,然后我用这些信息来改进我们的 CLAUDE.md 和内部工具。
更深入一点,Claude Code 将所有会话历史存储在 ~/.claude/projects/ 中,以便利用原始的历史会话数据。我有一些脚本会对这些日志进行元分析,寻找常见的异常、权限请求和错误模式,以帮助改进面向Agent的上下文。
核心要点:
使用
claude --resume和claude --continue来重启会话和挖掘埋藏的历史上下文。
● 钩子 (Hooks)
钩子非常重要。我个人项目不用它,但它们对于在一个复杂的企业级代码库中引导 Claude 至关重要。它们是确定性的 “必须做” 的规则,与 CLAUDE.md 中的 “应该做” 的建议互为补充。
我们使用两种类型的钩子:
- 提交时阻断钩子 (Block-at-Submit Hooks) 这是我们的主要策略。我们有一个
PreToolUse钩子,它会包裹任何Bash(git commit)命令。它会检查一个/tmp/agent-pre-commit-pass文件,这个文件 只有 在所有测试都通过时,我们的测试脚本才会创建。如果文件不存在,钩子就会阻止提交,迫使 Claude 进入一个“测试并修复”的循环,直到构建通过。 - 提示钩子 (Hint Hooks) 这些是简单的、非阻塞的钩子,如果Agemt正在做一些次优的操作,它们会提供“即发即忘”式的反馈。
�我们 刻意不使用 “写入时阻断” 的钩子(例如,在 Edit 或 Write 操作上)。在Agent执行计划中途阻断它,会使它困惑甚至“沮丧”。更有效的方法是让它完成它的工作,然后在提交阶段检查最终的、完整的结果。
核心要点:
使用钩子在提交时强制执行状态验证(提交时阻断)。避免在写入时阻断——让 Agent 完成它的计划,然后再检查最终结果。
● Plan模式
对于任何使用 AI IDE 进行的“大型”功能变更,规划都是必不可少的。
对于我的个人项目,我只使用内置的Plan模式。这是一种在 Claude 开始工作前与它对齐的方式,既定义了 如何 构建某样东西,也定义了它需要停下来向我展示工作的“检查点”。经常使用这个功能可以培养一种强大的直觉,即需要提供多少最少的上下文才能得到一个好的计划,而不会让 Claude 在实现阶段搞砸。
在我们的工作代码库中,我们已经开始推广一个基于 Claude Agent SDK 构建的自定义规划工具。它与原生规划模式类似,但经过了大量提示工程,使其输出与我们现有的技术设计格式保持一致。它还能开箱即用地强制执行我们的内部最佳实践——从代码结构到数据隐私和安全。这让我们的工程师可以像一位资深架构师一样,“凭感觉规划”一个新功能(至少我们的宣传是这么说的)。
核心要点:
对于复杂的变更,总是使用内置的Plan模式,在Agent开始工作前先就计划达成�一致。
● 技能 (Skills)
我同意 Simon Willison 的观点:Skills(也许)比 MCP 更重要 。
如果你一直关注我的文章,你会知道我已经逐渐放弃在大多数开发工作流中使用 MCP,而是倾向于构建简单的 CLI(正如我在《AI 读不懂你的文档》中论述的那样)。我对Agent自主性的心智模型已经演变为三个阶段:
- 单次提示 (Single Prompt) :在一个巨大的提示中给Agent所有上下文。(脆弱,无法扩展)。
- 工具调用 (Tool Calling) : “经典”的Agent模型。我们手动制作工具,为Agent抽象出现实世界。(更好,但创造了新的抽象和上下文瓶颈)。
- 脚本化 (Scripting) :我们给Agent访问原始环境的权限——二进制文件、脚本和文档——然后它 动态地 编写代码来与它们交互。
基于这个模型,Agent Skills 显然是下一个重要功能。它们是“脚本化”这一层的正式产品化。
如果你像我一样,已经倾向于使用 CLI 而非 MCP ,那么你其实一直在不自觉地享受着 Skills 带来的好处。SKILL.md 文件只是一个更有组织、可共享、可发现的方式来记录这些 CLI 和脚本,并将它们暴露给智能体。
核心要点:
Skills 是正确的抽象。它们将基于“脚本化”的智能体模型正式化,这种模型比 MCP 所代表的僵硬的、类似 API 的模型更健壮、更灵活。
● 模型上下文协议 (MCP)
Skills 并不意味着 MCP 已死。以前,许多人构建了糟糕的、上下文沉重的 MCP,包含几十个只是简单镜像 REST API 的工具(read_thing_a() , read_thing_b() , update_thing_c() )。
“脚本化”模型(现在由 Skills 正式化)更好,但它需要一个安全的方式来访问环境。对我来说,这正是 MCP 新的、更专注的角色。
一个 MCP 不应该是一个臃肿的 API,而应该是一个简单、安全的网关 ,提供几个强大的、高层次的工具:
download_raw_data(filters…)take_sensitive_gated_action(args…)execute_code_in_environment_with_state(code…)
在这个模型中,MCP 的工作不是为智能体抽象现实;它的工作是管理认证、网络和安全边界,然后让开。它为智能体提供了入口点 ,然后智能体利用它的脚本能力和 markdown 上下文来完成实际工作。
我唯一还在使用的 MCP 是用于 Playwright 的,这很合理——它是一个复杂的、有状态的环境。我所有无状态的工具(如 Jira、AWS、GitHub)都已迁移到简单的 CLI。
核心要点:
使用扮演数据网关角色的 MCP。给智能体一两个高层次的工具(比如一个原始数据转储 API),然后让它基于这些工具编写脚本。
● Claude Code (Agent) SDK
Claude Code 不仅仅是一个交互式的 CLI;它也是一个强大的 SDK——现为 Claude Agent SDK,可以用来构建全新的Agent——无论用于编码还是非编码任务。对于大多数新的个人项目,我已经开始用它作为我的默认Agent框架,而不是像 LangChain/CrewAI 这样的工具。
我主要在三个方面使用它:
- 大规模并行脚本 对于大规模重构、bug 修复或迁移,我不使用交互式聊天。我编写简单的 bash 脚本,并行调用
claude -p "in /pathA change all refs from foo to bar"。这比试图让主Agent管理几十个子Agent任务更具扩展性和可控性。 - 构建内部聊天工具 这个 SDK 非常适合将复杂的流程包装成一个简单的聊天界面,供非技术用户使用。比如一个安装程序,在出错时可以回退到 Claude Agent SDK 来为用户修复问题 。或者一个内部的“家庭版 v0”工具,让我们的设计团队可以在我们自家的 UI 框架中“凭感觉”编写前端模型,确保他们的想法是高保真的,并且代码能更直接地用于前端生产。
- 快速Agent原型设计 这是我最常见的用法,并且不限于编码。如果我对任何Agent任务有想法(例如,一个使用自定义 CLI 或 MCP 的“威胁调查Agent”),我会使用 Claude Code SDK 快速构建和测试原型,然后再投入到一个完整的、已部署的框架中。
核心要点:
Claude Agent SDK 是一个强大的、通用的Agent框架。用它来批量处理代码、构建内部工具,以及在选择更复杂的框架之前快速原型化新的Agent。
● Claude Code GHA (GitHub Action)
Claude Code GitHub Action (GHA) 可能是我最喜欢也是最被低估的功能之一。它的概念很简单:就是在 GHA 中运行 Claude Code。但正是这种简单性使其如此强大。
它与 Cursor 的 Background Agent 或 Codex 的托管 Web UI 类似,但可定制性要强得多。你控制整个容器和环境,这让你能接触到更多数据,并且至关重要的是,比任何其他产品提供更强的沙盒和审计控制。此外,它支持所有高级功能,如 Hooks 和 MCP。
我们用它来构建自定义的“随处可发 PR”的工具。用户可以从 Slack、Jira、甚至 CloudWatch 告警触发一个 PR,然后 GHA 会修复 bug 或添加功能,并返回一个经过完整测试的 PR。
由于 GHA 的日志就是完整的Agent日志,我们有一个运营流程,在公司层面定期审查这些日志,寻找常见的错误、bash 错误或不一致的工程实践。这创建了一个数据驱动的飞轮:Bugs → 改进的 CLAUDE.md / CLIs → 更好的Agent 。
$ query-claude-gha-logs --since 5d | claude -p “看看其他 Claude 卡在了哪里,修复它,然后提交一个PR”
核心要点:
GHA 是将 Claude Code 投入生产运营的终极方式。它将其从个人工具转变为你工程系统中一个核心的、可审计的、自我改进的部分。拥有无限自由的可能性

● settings.json
最后,我有一些特定的 settings.json 配置,我发现在个人和专业工作中都至关重要。
- HTTPS_PROXY/HTTP_PROXY : 这对调试非常有用。我会用它来检查原始流量,看看 Claude 究竟发送了什么Prompt。对于Background Agent,它也是一个强大的细粒度网络沙盒工具。
- MCP_TOOL_TIMEOUT/BASH_MAX_TIMEOUT_MS : 我调高了这些值。我喜欢运行长而复杂的命令,而默认的超时时间通常过于保守。
- ANTHROPIC_API_KEY : 在工作中,我们使用企业 API 密钥。这将我们从“按席位付费”的许可证模式转变为“按使用量付费”的模式,这更适合我们的工作方式。
- “permissions” : 我会偶尔自我审计一下我允许 Claude 自动运行的命令列表。
- (实际上
env还有许多非常有用的环境变量属性)
核心要点:
你的
settings.json是进行高级定制的强大工具。
结语
内容很�多,但希望对你有用。如果你还没有开始使用像 Claude Code 或 Codex CLI 这样的基于命令行的 Code Agent,你或许应该开始了。这些高级功能很少有好的指南,所以学习的唯一方法就是亲身投入进去。